Is Github’s business model still viable?
2026-04-05People are dunking on Github. “Zero 9’s uptime”. And yeah it’s not great, as of writing this it’s 89.24% over the past 90 days according to “The Missing GitHub Status Page”.
But people are misunderstanding what’s going on. Blaming it on the Microsoft takeover or on Github letting go of key staff members. That may be part of it. But I’d say they’re sideshows to the main act.
Let me explain. Below are recent plots of growth in key numbers from Railway and Render.
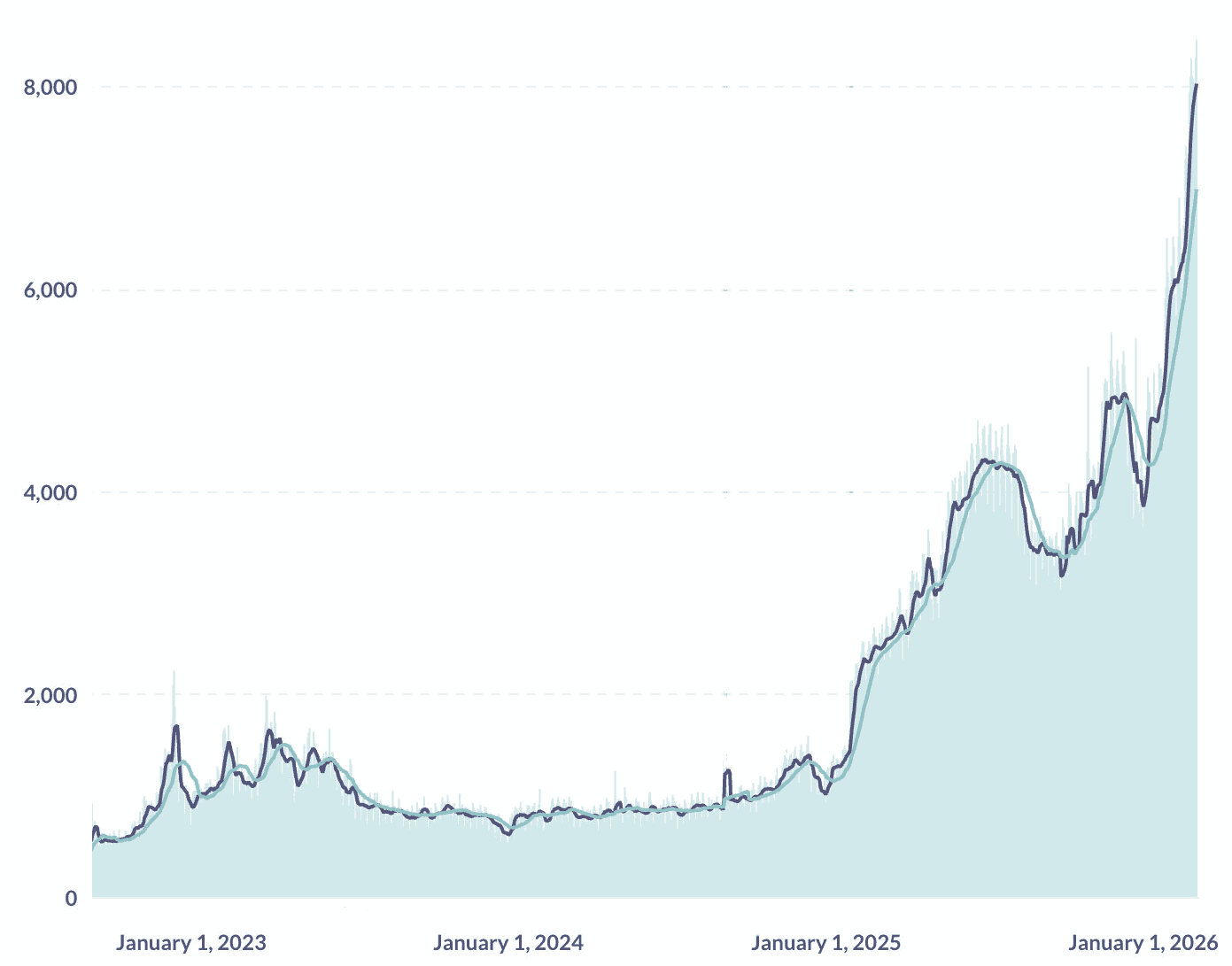 Railway's growth from @JustJake (CEO at Railway)
Railway's growth from @JustJake (CEO at Railway)
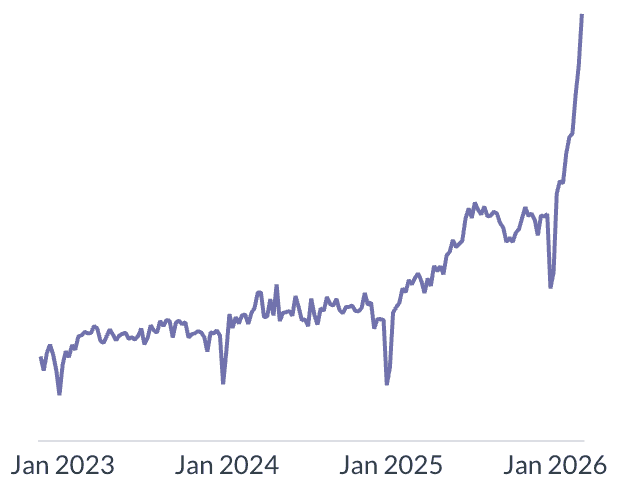 Render's growth from @anuraggoel (CEO at Render)
Render's growth from @anuraggoel (CEO at Render)
See that almost vertical line starting around Jan 2026? What happened? Claude Code happened. Vibecoding happened. Code produced by matrix multiplications happened. It was already there, but the latest models are self-driving to an extent that enables a much wider range of people to produce code. Way more is being built, and being built way faster.
Now, having something on Railway or Render means you actually cared enough to spin up a server. Most vibecoding is not that. There’s no deployment for gstack (Garry Tan’s ultravibed thing) nor any server hosting necessary for autoresearch or the new caveman skill. But there is a Github repository for all of those, plus one for everyone and their mom’s vibecoded home-project0.
Here’s Pete Steinberger’s Github contribution graph (of OpenClaw fame):
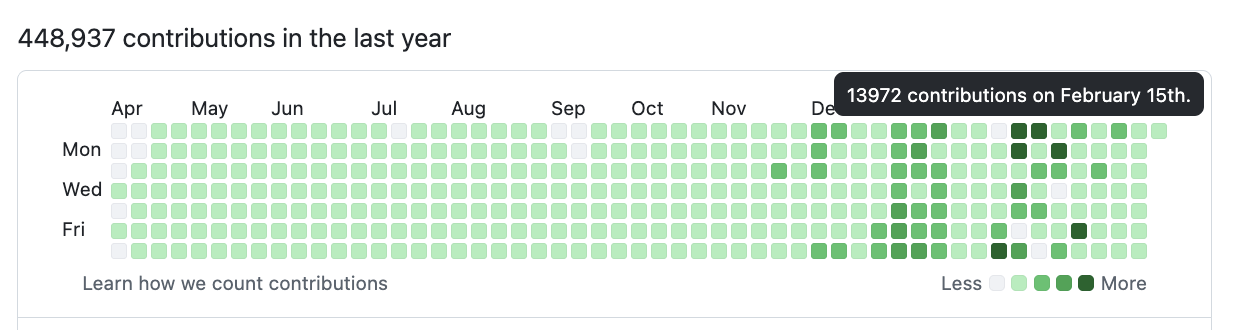
Credit to @asishcodes on Twitter (and probably many others) for pointing this ridiculous stat out.
So, imagine the above growth plots, but make slope 10 times steeper and multiply the y-axis by 1,000x 1. Now you have the plot for Github. This is growth at an unfathomable scale. Today, there are both more users pushing to Github and every user on the platform is pushing way more code, more frequently. All due to coding agents.
Github is experiencing IMMENSE growing pains. It’s no laughing matter. There’s nothing to dunk on there. This is an org that is already handling absolutely immense volume, and now that volume is probably doubling or tripling within a very short timeframe.
Okay, and what does all that have to do with their business model?
The business model v1
Historically, Github has basically been a tiered freemium model – and at the most basic level it still is. The freemium model thinking is – free usage is a gateway to paid tiers, and those basically sponsor the free tier. That made sense in the olden days – for one, back then you actually had to type in something – with your hands – to put something on Github. Which meant that the ratio of hobby-projects to professional-projects was modest. 10:1 maybe? There was only so much free time to manually type into files in a repository. And at work you wanted a private repo with CI, and that costs money. And so Github made money.
Fast forward to today, the amount of hobby projects is skyrocketing. It takes Claude five minutes to put up a Tetris clone, but it’s hexagonal and the blocks are coming in from all sides. Whereas building a business takes time. And you’re not gonna go on a paid plan for Hextris, because it’s not a business it’s just a hobby project that’s not making any money. And you might say “But it’s much easier to make money in the era of LLMs” — but it’s nothing compared to how much easier producing code has become. If anything, there’s probably going to be less need for something like Github Enterprise – likely the main revenue and profit driver for Github – because teams are getting smaller, there’s less on-premise need, and just generally fewer big-corporaty setups because everyone can just vibecode their SaaS. They don’t need a 100 person dev team to build Okta or Hubspot anymore2.
So, the core Github business model has died. That business model is no longer viable.
The business model v2
The new business model foregoes all that. Github is now a data play. Ingest and store as much code as you can, and have it be training data for models. Use the data to build Copilot and sell it.
Data plays can be quite good business, just look at the Reddit + OpenAI deal. Not good for users, but good for business.
For Github in particular, there are lots of caveats to that of course – most of the code is open source – OpenAI and Anthropic have ingested it already and will continue to ingest it so there’s no way to monetize. And is it even valuable data if all the new code is vibecode anyways? You can’t teach a model to be better at coding by having ingest code it produced itself. Even if you could, you wouldn’t need to go through Github3.
I think that’s a fairly sound business strategy.
I’m quite tired of the trope “if you’re not paying, you are the product”. But it does apply here – and while I’m not very afraid of my data floating around out there (on Github or on the internet at large) nor afraid of public internet data being used for AI training – I am quite saddened to know that there’s now a disconnect between what I’m paying for and what actually drives value for the business, in this case Github. The ideal business model really is – you pay for the value the business creates. It’s perfect incentive alignment between customer and provider.
A toast to a now dead business model, and a toast to the sweating SREs trying to keep Github afloat.
Update (May 14th 2026)
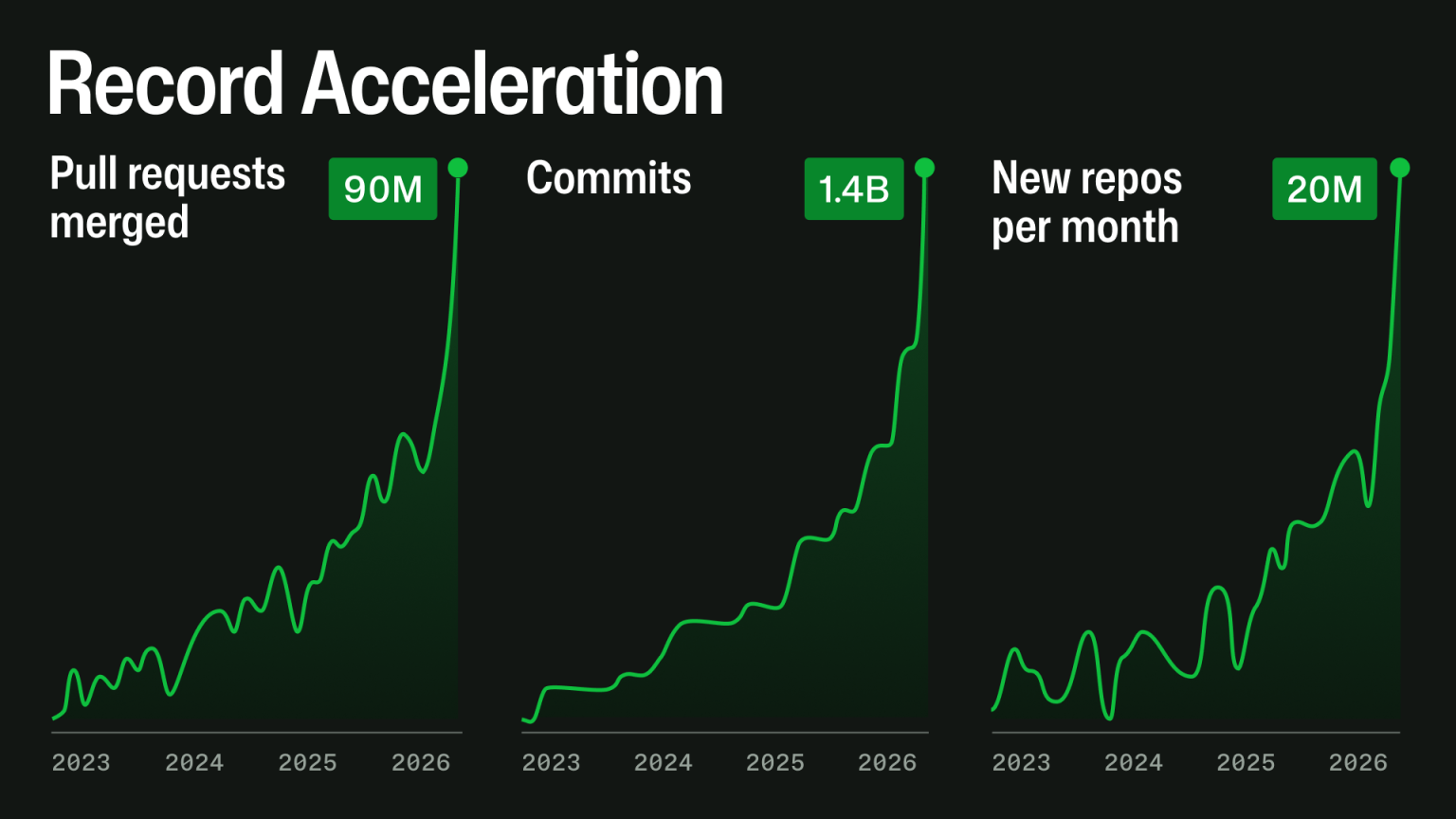
About 20 days after writing this, Github actually posted plots of their actual growth on their blog. Nothing surprising. Well, perhaps one thing – the commits trend doesn’t look as bad as I expected. I’d guess that’s because with LLMs we tend to get these larger one-off commits, rather than the more gradual, human “commit-as-you-go” approach.
Footnotes
0 Some caveats would be: A) Render and Railway may be primarily be experiencing growth from deployments of OpenClaw, in which case their growth doesn’t translate to more repos and commits on Github. B) The actual number of new repositories on Github doesn’t seem to be exploding in the way I’d expect, but I still expect pushes and number of commits to be.
1 How do I get to 10x slope and 1000x y-intercept? For slope, let’s look at repositories – I’m saying for every 1 repository that gets deployed to Railway or Render there are 9 that didn’t. For the y-intercept, we’re seeing Railway at 5,000 paying customers before the growth spurt. My back-of-the-envelope calculations puts Github at 5,000,000 paid seats.
2 Yes, yes, you can’t really vibecode an entire auth suite or CRM. Or at least you probably shouldn’t. But I definitely believe it is true that you don’t need the same amount of people build e.g. a CRM anymore. Have you seen the amount of new CRMs popping up? And it wasn’t for lack of CRMs in the first place. So yes, SaaSpocalypse is at least partially right. Not all the way right, but partially.
3 Maaaaaaybe, there is value in vibecode on Github because that
vibecode was chosen to be pushed to Github — so maybe a human tested it and
found it to be working — or maybe they looked at it and found it to be
reasonable code. Which could make it just slightly higher “alpha” than the
raw code coming out of an LLM. In any case, the “alpha” would be very low,
and it would probably be best to filter on certain repositories — e.g.
selecting ones with lots of activity from many people — signaling an actually
functioning project that produces value to those people.
And then of course Apple had to go and show that it is possible to
have the snake eat its own tail while I was writing this blog post https://arxiv.org/abs/2604.01193.